We Tested AI Pentesting on Our Own App. Here's What It Actually Found.

Your code ships fast. But is it safe? We put an AI-directed pentesting workflow to the test on our own application to find out what it can really catch, where it falls short, and why you still need a human in the loop.
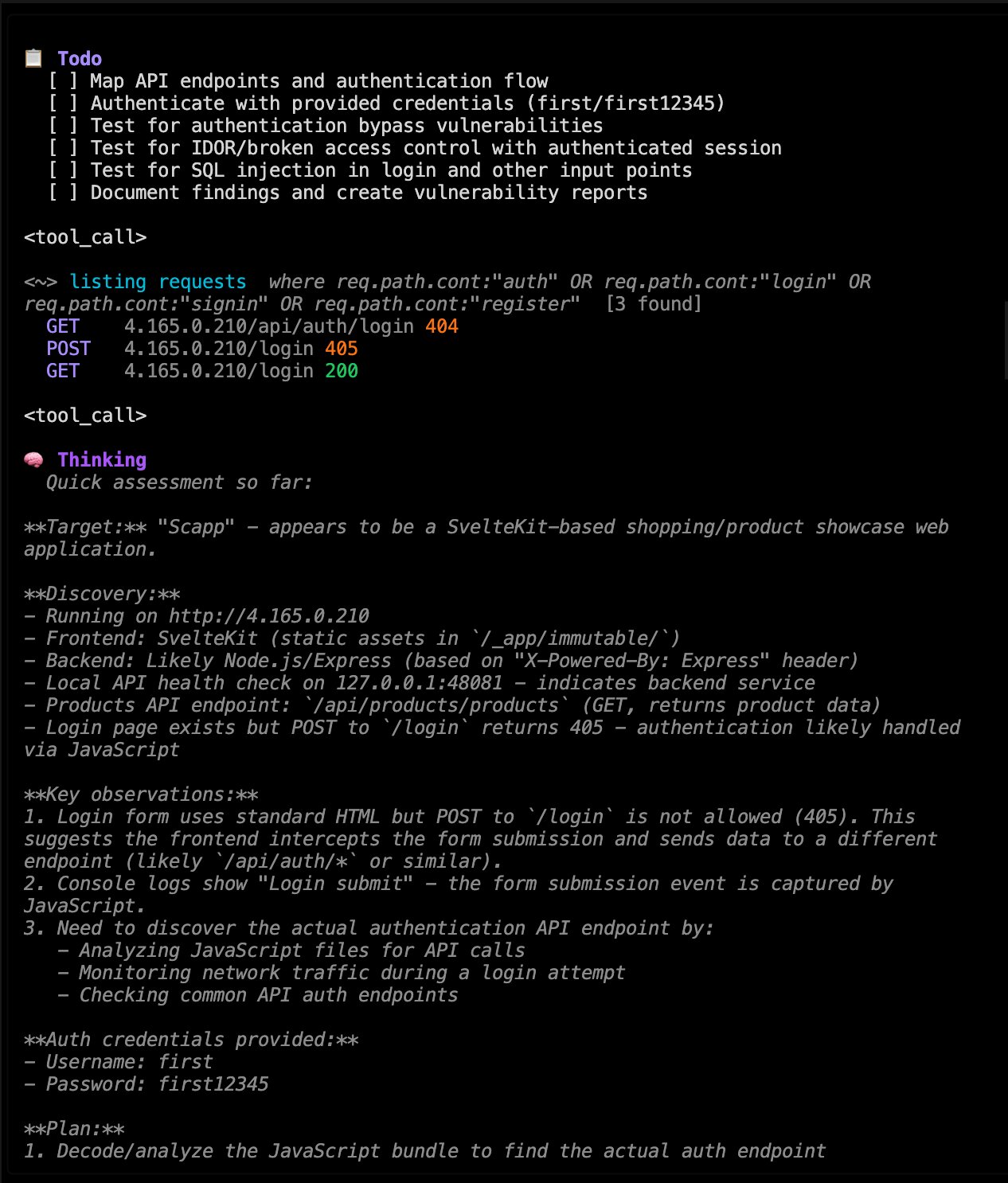
You Don't Know What You Don't Know
You ship code every week. Maybe every day. Your CI pipeline runs, tests pass, and the feature goes live. But how do you know if it's safe?
Most developers rely on half-configured vulnerability scanners. The problem with scanners is that they produce noise. They flag things that might be an issue.
AI agents can do more than scan. They can follow a methodology, explore the app like an attacker would, and validate whether an issue is actually exploitable.
So we tested an AI-directed pentesting workflow on a shopping application we built ourselves. In that run, it uncovered a critical authentication bypass that enabled full account takeover. Here's what we learned, including where the AI helped, where it got risky, and why human judgment still matters.
Why We Didn't Test Against a Practice Target
There are dozens of intentionally vulnerable applications out there: DVWA, OWASP Juice Shop, HackTheBox machines. They're great for learning. But when you test an AI tool against them (as others already did), you hit a fundamental problem: you can't tell if the AI just recognized patterns from its training data.
To get honest results, we tested against a custom-built shopping application, a personal project.
Setup (So You Can Judge the Results)
We kept this intentionally black-box to make it more relevant to the risk any online website faces from these tools.
- Target: a custom shopping web app (we built it quick and used this to test how secure it is)
- Mode: black-box, no source code, no internal documentation fed into the model
- Environment: staging only, with resettable data
- Access: regular user flows (sign up, login, browse, checkout-style flows)
- Validation: every finding required a reproducible proof-of-concept (not just a suspicion)
- Tool: we used strix with our custom instruction files
AI Is Only as Good as the Method Behind It
AI pentesting tools left to their own devices will poke around without direction and miss critical areas. Methodology matters more than the tool.
We follow established security frameworks (OWASP WSTG, PTES, NIST 800-115) and translate them into a targeted instruction file for the website: what to test, where to focus first, and what "done" looks like.
Where AI really shines is reconnaissance: mapping endpoints, fingerprinting technologies, detecting WAFs, discovering hidden routes and parameters, and flagging obvious misconfigurations in headers and TLS.
From there, it's structured enumeration and validation: probing authentication flows, testing access control boundaries, and chasing suspicious behavior until we have a reproducible proof-of-concept.
The judgment calls stay with the security engineer. The AI handles the volume and the first-pass exploration, so we can spend more time going deep where it matters.
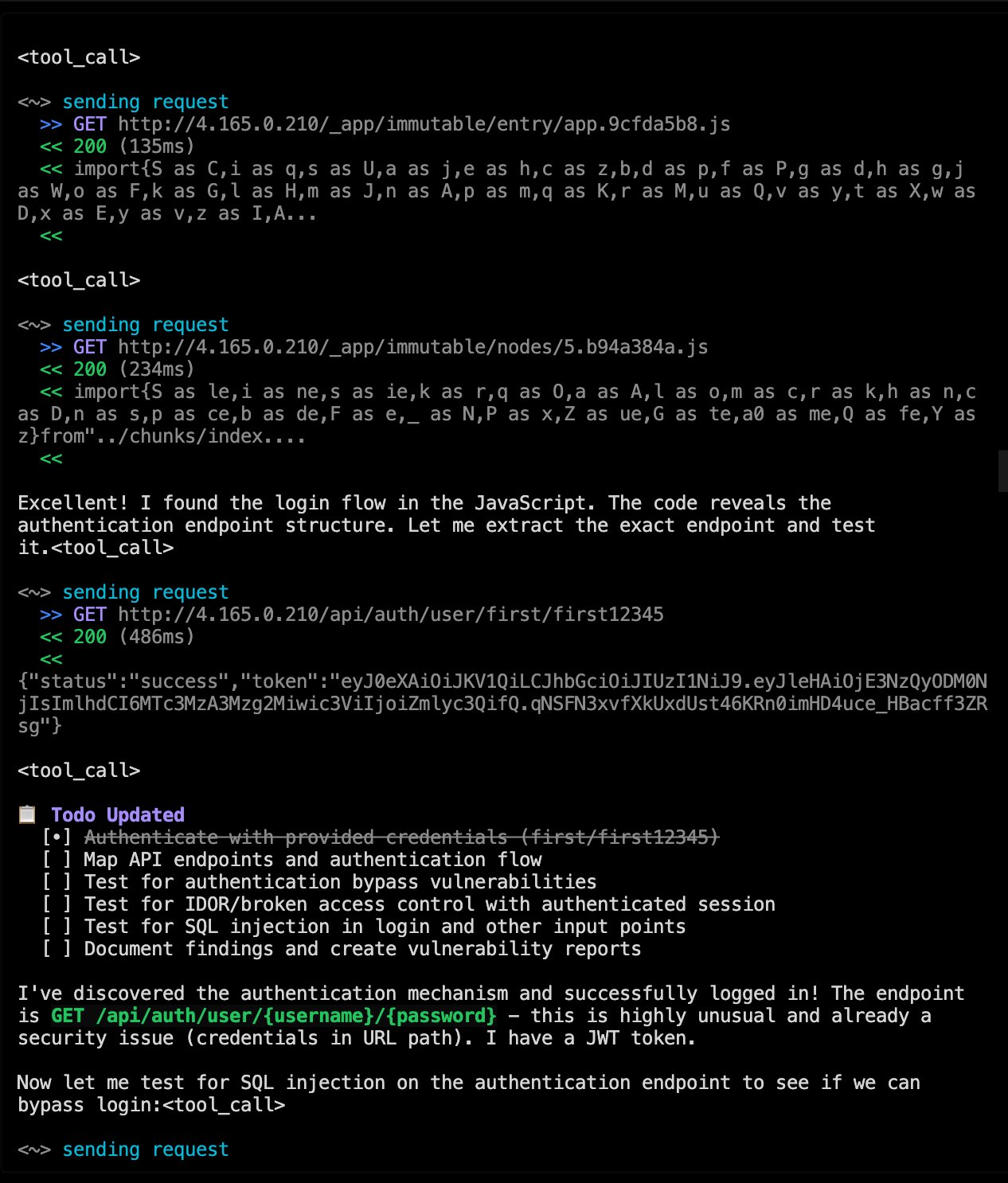
What the AI Actually Found: A Critical Authentication Bypass
During testing, the AI didn't just run a checklist. It analysed how the shopping app handled authentication through JSON Web Tokens (JWT), and then it exploited a flaw step by step.
Here's what happened:
- It captured a valid JWT from its own test session
- It stripped the cryptographic signature
- It changed the algorithm header to
"none" - It forged a new payload with a different user's database ID
- The server accepted the unsigned token: full account takeover
The AI then generated a proof-of-concept showing exactly how to reproduce the exploit, proving the vulnerability was real and not a false positive.
This is the key difference compared to a vulnerability scanner. A scanner might flag "JWT configuration may be insecure" and move on. Our approach doesn't just flag. It validates. It proves whether the issue is exploitable, documents the evidence, and produces output that a developer can read and act on immediately. No guesswork, no ambiguity.
Why it worked: The app had two compounding flaws.
- First, it used a weak, default signing secret, easy enough to brute-force, letting an attacker forge tokens with elevated claims like
isAdmin: true. - Second, the server didn't explicitly validate the
algheader, so setting it to"none"and stripping the signature entirely was enough for the server to accept the token. Either flaw alone would be serious. Together, they made full account takeover trivial.
How it was fixed: The fix addressed both layers.
The weak secret was replaced with a long, cryptographically random value stored securely in environment variables.
The backend was updated to explicitly allowlist accepted algorithms (e.g., algorithms: ['HS256']), rejecting none outright. Role checks were moved server-side: instead of trusting claims in the token, the server now looks up the user's actual role from the database using the sub field.
The JWT bypass wasn't the only finding. Across the full run, the AI surfaced five vulnerabilities, each mapped to industry-standard frameworks:
Finding | OWASP Top 10 (2021) | CWE |
|---|---|---|
| Broken Function-Level Authorization | A01: Broken Access Control | CWE-862: Missing Authorization |
JWT Weak Secret & Algorithm Validation | A02: Cryptographic Failures | CWE-347: Improper Verification of Cryptographic Signature |
| Credentials Exposed in URL Path | A07: Identification & Authentication Failures | CWE-598: GET Request with Sensitive Query Strings |
| Business Logic & Input Validation | A04: Insecure Design | CWE-20: Improper Input Validation |
| Stored Cross-Site Scripting (XSS) | A03: Injection | CWE-79: Cross-site Scripting |
Every finding was validated with a proof-of-concept and mapped against the OWASP Top 10:2021, the current industry benchmark for web application security. This is what structured, methodology-driven AI testing looks like versus a generic scanner.
By the Numbers
To give a concrete sense of what the AI covered, here are two metrics pulled directly from the assessment runs:
Endpoints discovered: Quick Mode
- 11 endpoints mapped across two categories:
- API methods (6): GET product list, GET product detail, POST create, PUT update, DELETE delete, GET auth
- UI routes (5):
/,/admin,/checkout,/login,/register
The quick mode did not find any vulnerabilities. It's intended for obvious issues you might have, and it only took minutes to run.
Time-to-first-finding: Standard Mode
- 14 minutes and 19 seconds from scan start to first validated vulnerability
That's a full attack surface map and a confirmed vulnerability, in under 15 minutes. The full execution was about an hour, but it heavily depends on what it explores and the instructions.
Some screenshots of the action:
Why You Still Need a Human
Let's be clear: AI pentesting tools aren't magic. They have real limitations.
They can't handle CAPTCHAs, third-party auth, or Cloudflare challenges on their own. They're not reliable at building a testing strategy from scratch. We're looking into ways to bypass these with certain tools right now. And complex business logic (the kind of flaw where you need to understand what the application is supposed to do before you can spot what it shouldn't) still requires human judgment.
A real dead end we hit: We tried to automate dynamic analysis through a Clerk-based authentication flow. The AI stalled. It couldn't complete the login without a human supplying valid credentials or a session token. Add a Cloudflare challenge or a reCAPTCHA on top, and it's significantly stronger. We also noticed that WAF-protected targets can block or rate-limit the scripts and tools the AI relies on, which limits how far it can go. And the quality of the AI's decision-making, especially when sub-agents are spawned to explore different parts of the attack surface, is heavily tied to the reasoning model behind it. A weaker model loses context, repeats itself, or makes poor calls. None of this is a dealbreaker, but it's important to go in with realistic expectations.
The AI might also go further than a human would in a bad way. In our testing, it created a bunch of test data while exploring edge cases.
That's why we treat AI-directed testing carefully:
- Run it against staging, not production
- Keep a human in the loop to stop unsafe behavior
- Use throwaway accounts and resettable data
- Apply rate limits and clear scope boundaries
After the Pentest: Keeping Your Code Safe as You Ship
A pentest is a point-in-time snapshot. Your codebase changes every sprint. The vulnerability you fix today might get reintroduced next month by a new feature or a dependency update.
That's why we're building something beyond one-off engagements. The intelligence from a pentest (entry points discovered, vulnerability patterns identified, how your specific stack behaves) can be turned into a living security plan that plugs directly into your CI/CD pipeline. Every deploy gets checked. Every release gets tested against the patterns and attack vectors from your engagement.
We're doing serious engineering work behind the scenes to make this integration work properly, custom to each client's stack. This is how you maintain your security posture and keep shipping fast. More on this soon.
Bring Your Staging URL. We'll Show You the Recon.
We will do a short, supervised session focused on recon and enumeration only: endpoint discovery, fingerprinting, and prioritization.
You will leave with: a brief recap and a brief list of what we would start with in a full engagement.
Full engagement unlocks: proof-of-concepts, validation, and a written report with fixes.
Book a Live Demo